First Look: Self Hosting Large Language Models
Why Do This
The proliferation of easily accessible generative artificial intelligence (GenAI), particularly large language models (LLM), has ushered in significant productivity gains for many of us, yet, ask any CISO or security architect and you will find concerns with employees misusing GenAI-as-a-service solutions, unknowingly leaking corporate information despite their best intentions. The knee jerk reaction is to ban the use of GenAI in the work environment, but denying access to such powerful tools would only put one at a competitive disadvantage. We are already seeing larger corporations acquiring graphics processing units (GPU) - hardware which excel at running GenAI models, to enable GenAI use cases, the big one being local AI inference. In layman’s terms, querying and expecting results from GenAI running on hardware you own.
Running LLMs
While larger and more capable LLMs continue to make the headlines, significant efforts have been made on the other end of the scale, optimizing LLMs to be small enough to run on consumer-grade hardware (Raspberry Pis anyone?) whilst maintaining acceptable performance. LLM Explorer maintains a list of “Small Language Models”, which you can sort by the amount of VRAM needed.
Hopeful that the models can be run on consumer hardware, I set out to replicate a ChatGPT-like experience all within the confines of my lab environment, starting with acquiring a GPU. I ultimately picked the NVIDIA RTX4080 Super due to:
- its support for CUDA which promises better compatibility, as well as
- it having (close to) 16GB of VRAM, which is large enough to run many of the popular language models, sometimes even multiple instances of them simultaneously.
Having the hardware sorted, next step is to get LLMs to run on the GPU. A quick research reveals that the beauty that is Ollama. It is an open-source “LLM runner” which makes it super simple to spin up LLMs on local hardware and provides easy to use interfaces to receive and process queries.
$ ollama run phi3 "what are you in 20 words or less"
I am an AI, designed to process and respond to data. I facilitate
information retrieval and interaction for users globally. My purpose is
assisting humans through digital communication, enhancing knowledge
accessibility.
Ollama also has a HTTP API, listening on port 11434 by default, which will come in handy in the next section.
$ curl localhost:11434
Ollama is running
The ollama ps command shows if the LLMs are running on the GPU or CPU. If an LLM is too large to be completely loaded within the GPU VRAM, the system RAM will be used to load the rest of it, which slows down performance significantly, so picking a model with the right size is vital.
$ ollama ps
NAME ID SIZE PROCESSOR UNTIL
phi3:latest 4f2222927938 6.6 GB 100% GPU 4 minutes from now
User Interface
With the LLM running, I shifted my attention to finding a web interface to interact with it, and Open WebUI seems to be most popular option.
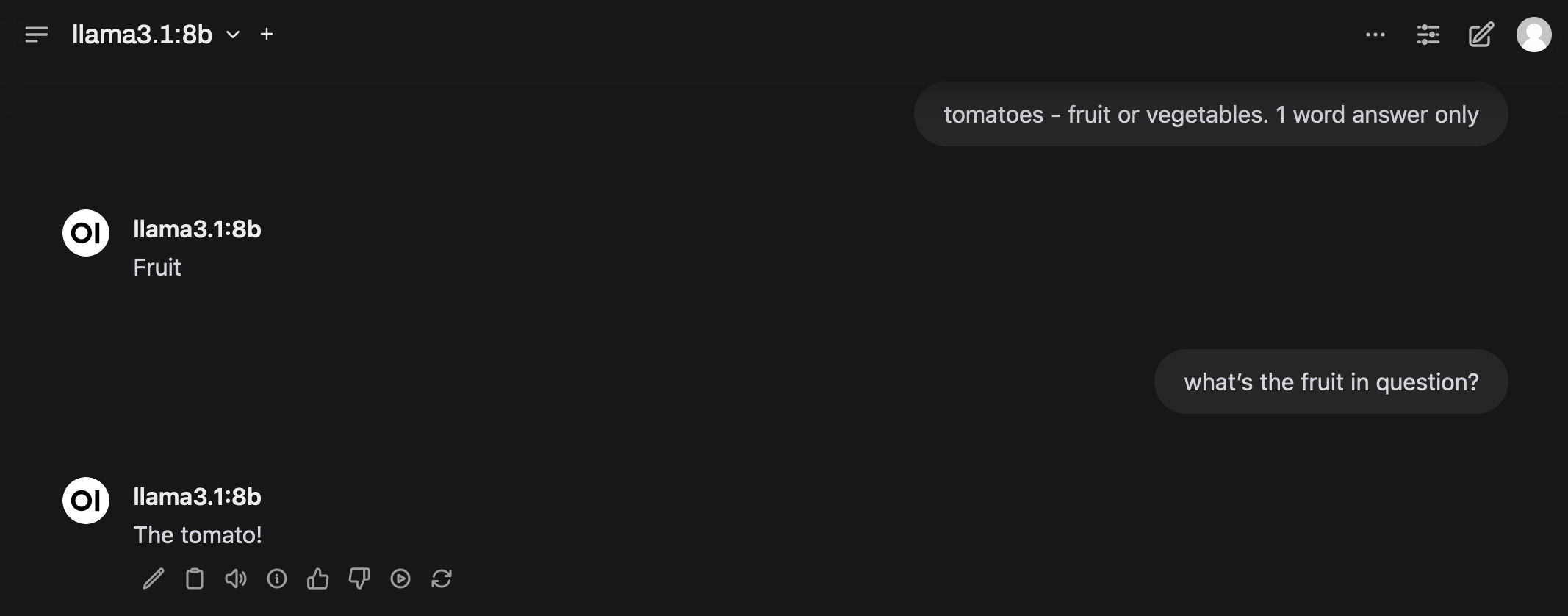
Under the hood, Open WebUI connects to Ollama via the aforementioned HTTP API on port 11434 to send queries to and receive responses from the LLM. One interesting discovery was how the LLM keeps track of context - digging deeper into the API calls Open WebUI makes reveals every message exchanged within a session is included in the messages array in subsequent API calls to Ollama, as seen in the request payload sent for the second query in the screenshot above:
POST /api/chat
{
"model": "llama3.1:8b",
"messages": [
{
"role": "user",
"content": "tomatoes - fruit or vegetables. 1 word answer only"
},
{
"role": "assistant",
"content": "Fruit"
},
{
"role": "user",
"content": "what\u2019s the fruit in question?"
}
],
"options": {},
"stream": true
}
The number of messages that can be sent and how this relates to tokens/contexts will be a rabbit hole worth exploring in the future.
LLM At The Edge
Serendipitously, I had also recently switched to a Macbook Pro for my work laptop, and those Apple silicon pack quick a punch in the VRAM department, slightly surpassing the NVIDIA GPU. This means the Macbook Pro can basically load the same type and number of LLMs as the NVIDIA GPU, though a quick benchmark with llm-benchmark puts the NVIDIA GPU in front:
|
|
Having two separate LLM providers does however opens up new possibilities for future experimentations.
Conclusion
This turned out to be simpler to set up than I thought. Having a self-hosted LLM means I can more freely explore its capabilities without worrying about leaking potentially sensitive data.
I will finish off with the following Docker Compose file which deploys the setup used in this post:
# docker-compose.yaml
services:
ollama:
image: ollama/ollama
runtime: nvidia # This tells Docker to use GPU
volumes:
- ./.tmp/ollama:/root/.ollama # Mount the Ollama volume
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: all
capabilities: [gpu]
restart: always
open-webui:
container_name: open-webui
image: ghcr.io/open-webui/open-webui:main
environment:
OLLAMA_BASE_URL: http://ollama:11434
WEBUI_AUTH: false
volumes:
- ./.tmp/open-webui:/app/backend/data
restart: always
ports:
- 8080:8080 # Access Open WebUI via http://localhost:8080
Note that the Docker Compose file will not work properly on MacOS, as Docker Desktop does not support GPUs at this stage. Ollama will have to be installed natively on MacOS, and the Open WebUI container configured to point to the Ollama instance on the host via the
OLLAMA_BASE_URLvariable.